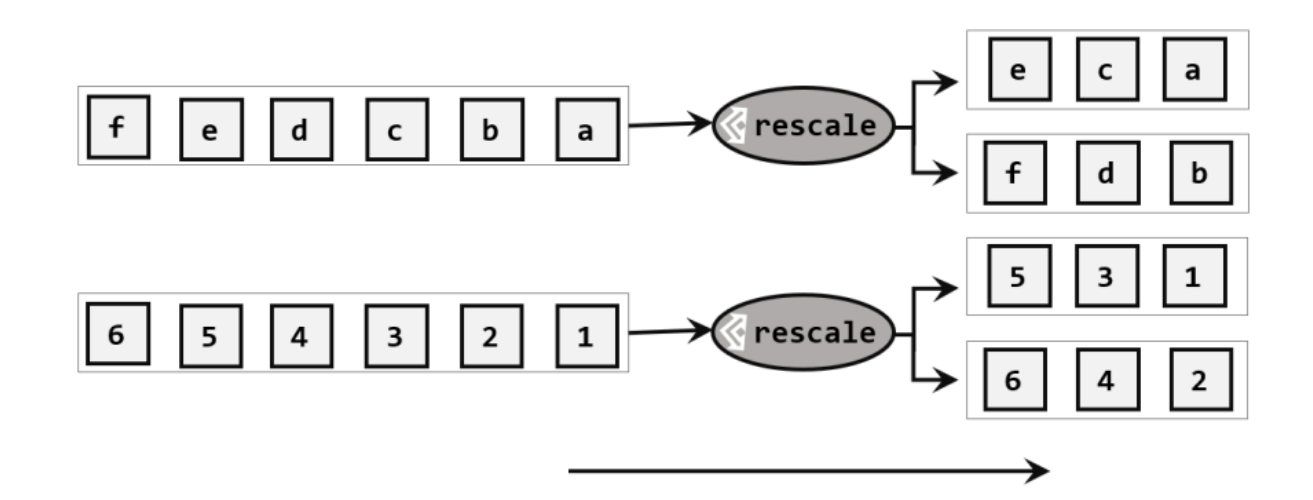
图论 专题(一)BFS和DFS的直观解释 https://blog.csdn.net/c406495762/article/details/117307841 Leetcode岛屿问题系列分析 https://blog.csdn.net/qq_39144436/article/details/124173504 多源广度优先 https://blog.csdn.net/peko1/article/details/121989497 拓扑排序 https://blog.csdn.net/chenweiye1/article/details/113563417 Trie树 https://blog.csdn.net/weixin_47251999/article/details/113364363 字典树 https://baike.baidu.com/item/%E5%AD%97%E5%85%B8%E6%A0%91/9825209?fromtitle=Trie%E6%A0%91&fromid=517527&fr=aladdin 广度优先搜索算法 (Breadth-First-Search,缩写为 BFS),是一种利用队列实现的搜索算法 。简单来说,其搜索过程和 “湖面丢进一块石头激起层层涟漪” 类似。
BFS常用于找单一的最短路。约束:每条路上的权重必须是1 一般来说BFS可以用以下模板思路来解决 深度优先 搜索算法 (Depth-First-Search,缩写为 DFS),是一种利用递归实现的搜索算法 。简单来说,其搜索过程和 “不撞南墙不回头” 类似。
DFS 用于找所有解的问题,它的空间效率高,但是找到的不一定是最优解,必须记录并完成整个搜索,故一般情况下,深搜需要非常高效的剪枝 BFS 的重点在于队列,而 DFS 的重点在于递归。这是它们的本质区别。 1.有向无环图
2.序列里的每一个点只能出现一次
3.任何一对 u 和 v ,u 总在 v 之前(这里的两个字母分别表示的是一条线段的两个端点,u 表示起点,v 表示终点)
求拓扑排序的思路:注意边的方向一定是a到其他节点 ),更新完入度=0的节点入队 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。
典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
分析(以下均来源参考文献5)
时间复杂度
构建Trie树时间复杂度是 O(n)(n是Trie树中所有元素的个数) 查询Trie树时间复杂度是 O(k)(k 表示要查找的字符串的长度) 缺陷
每个数组元素要存储一个 8 字节指针(或者是 4 字节,这个大小跟 CPU、操作系统、编译器等有关),且指针对CPU缓存并不友好。 在重复的前缀并不多的情况下,Trie 树不但不能节省内存,还有可能会浪费更多的内存。(比如,此种字符串第三个字符只有两种可能,而它要维护一个长26的数组。这还只是考虑纯字母的情况,如果是复合型字符串,则会浪费更多空间) 应用
第一,字符串中包含的字符集不能太大。如果字符集太大,那存储空间可能就会浪费很多。即便可以优化,但也要付出牺牲查询、插入效率的代价。 第二,要求字符串的前缀重合比较多,不然空间消耗会变大很多。 第三,通过指针串起来的数据块是不连续的。所以,对缓存并不友好,性能上会打个折扣。 第四,对于精确查找(如词频统计),用字符串hash/红黑树其实更好,Trie树比较适合的是查找前缀匹配的字符串(如 实现搜索引擎的搜索关键词提示功能) BFS和DFS在做题的时候一般可以相互转换,可以根据题干自行选择较优的那一种(比如最短路一般用广度优先) 先记录一下DFS的模板(模板内容均来源参考文献2) 二叉树
二叉树的 DFS 有两个要素:「访问相邻结点」和「判断 base case」。 第一个要素是访问相邻结点。二叉树的相邻结点非常简单,只有左子结点和右子结点两个。二叉树本身就是一个递归定义的结构:一棵二叉树,它的左子树和右子树也是一棵二叉树。那么我们的 DFS 遍历只需要递归调用左子树和右子树即可。 第二个要素是 判断 base case。一般来说,二叉树遍历的 base case 是 root == null。这样一个条件判断其实有两个含义:一方面,这表示 root 指向的子树为空,不需要再往下遍历了。另一方面,在 root == null 的时候及时返回,可以让后面的 root.left 和 root.right 操作不会出现空指针异常。 void traverse ( TreeNode* root) {
if ( root == NULL ) {
return ;
}
traverse ( root-> left) ;
traverse ( root-> right) ;
}
图
对于网格上的 DFS,我们完全可以参考二叉树的 DFS,写出网格 DFS 的两个要素: 首先,网格结构中的格子有多少相邻结点?答案是上下左右四个。对于格子 (r, c) 来说(r 和 c 分别代表行坐标和列坐标),四个相邻的格子分别是 (r-1, c)、(r+1, c)、(r, c-1)、(r, c+1)。换句话说,网格结构是「四叉」的。 其次,网格 DFS 中的 base case 是什么?从二叉树的 base case 对应过来,应该是网格中不需要继续遍历、grid[r][c] 会出现数组下标越界异常的格子,也就是那些超出网格范围的格子。 网格结构的 DFS 与二叉树的 DFS 最大的不同之处在于,遍历中可能遇到遍历过的结点。这是因为,网格结构本质上是一个「图」,我们可以把每个格子看成图中的结点,每个结点有向上下左右的四条边。在图中遍历时,自然可能遇到重复遍历结点。这时候,DFS 可能会不停地「兜圈子」,永远停不下来。–> 需要标记已经遍历过的格子 void dfs ( int [ ] [ ] grid, int r, int c) {
if ( ! inArea ( grid, r, c) ) {
return ;
}
dfs ( grid, r - 1 , c) ;
dfs ( grid, r + 1 , c) ;
dfs ( grid, r, c - 1 ) ;
dfs ( grid, r, c + 1 ) ;
}
boolean inArea ( int [ ] [ ] grid, int r, int c) {
return 0 <= r && r < grid. length
&& 0 <= c && c < grid[ 0 ] . length;
}
岛屿数量 https://leetcode.cn/problems/number-of-islands/?envType=study-plan-v2&id=top-100-liked“1”,“1” ,“0”,“0”,“0”],“1”,“1” ,“0”,“0”,“0”],“1” ,“0”,“0”],“1”,“1” ] class Solution {
public :
bool flag[ 90010 ] ;
void dfs ( int x, int y, vector< vector< char >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
cout<< x<< " " << y<< endl;
if ( x< 0 || x>= m|| y< 0 || y>= n|| grid[ x] [ y] == '0' || flag[ x* n+ y] ) return ;
if ( grid[ x] [ y] == '1' && ! flag[ x* n+ y] ) flag[ x* n+ y] = true ;
dfs ( x+ 1 , y, grid) ;
dfs ( x- 1 , y, grid) ;
dfs ( x, y+ 1 , grid) ;
dfs ( x, y- 1 , grid) ;
}
int numIslands ( vector< vector< char >> & grid) {
int res= 0 ;
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
if ( grid[ i] [ j] == '1' && ! flag[ i* n+ j] ) {
res++ ;
dfs ( i, j, grid) ;
}
}
}
return res;
}
} ;
class Solution {
public :
bool flag[ 90010 ] ;
void bfs ( int x, int y, vector< vector< char >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
queue< int > q;
q. push ( x* n+ y) ;
flag[ x* n+ y] = true ;
int dx[ 4 ] = { 1 , 0 , - 1 , 0 } , dy[ 4 ] = { 0 , 1 , 0 , - 1 } ;
while ( ! q. empty ( ) ) {
int t= q. front ( ) ;
q. pop ( ) ;
for ( int i= 0 ; i< 4 ; i++ ) {
int x= t/ n+ dx[ i] ;
int y= t% n+ dy[ i] ;
if ( x>= 0 && x< m && y>= 0 && y< n && grid[ x] [ y] == '1' && ! flag[ x* n+ y] ) {
q. push ( x* n+ y) ;
flag[ x* n+ y] = true ;
}
}
}
}
int numIslands ( vector< vector< char >> & grid) {
int res= 0 ;
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
if ( grid[ i] [ j] == '1' && ! flag[ i* n+ j] ) {
res++ ;
bfs ( i, j, grid) ;
}
}
}
return res;
}
} ;
岛屿的最大面积 https://leetcode.cn/problems/max-area-of-island/ class Solution {
public :
bool flag[ 2510 ] ;
void dfs ( int x, int y, vector< vector< int >> & grid, int & square) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
if ( x< 0 || x>= m|| y< 0 || y>= n|| grid[ x] [ y] == 0 || flag[ x* n+ y] ) {
return ;
}
square++ ;
flag[ x* n+ y] = true ;
dfs ( x+ 1 , y, grid, square) ;
dfs ( x- 1 , y, grid, square) ;
dfs ( x, y+ 1 , grid, square) ;
dfs ( x, y- 1 , grid, square) ;
}
int maxAreaOfIsland ( vector< vector< int >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
int maxSquare= 0 ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
int square= 0 ;
if ( grid[ i] [ j] == 1 && ! flag[ i* n+ j] ) {
dfs ( i, j, grid, square) ;
maxSquare= max ( maxSquare, square) ;
}
}
}
return maxSquare;
}
} ;
class Solution {
public :
bool flag[ 2510 ] ;
int bfs ( int x, int y, vector< vector< int >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
int square= 0 ;
queue< int > q;
q. push ( x* n+ y) ;
flag[ x* n+ y] = true ;
int dx[ 4 ] = { 0 , 1 , 0 , - 1 } , dy[ 4 ] = { 1 , 0 , - 1 , 0 } ;
while ( ! q. empty ( ) ) {
square++ ;
int t= q. front ( ) ;
q. pop ( ) ;
for ( int i= 0 ; i< 4 ; i++ ) {
int x= t/ n+ dx[ i] ;
int y= t% n+ dy[ i] ;
if ( x>= 0 && x< m && y>= 0 && y< n && grid[ x] [ y] == 1 && ! flag[ x* n+ y] ) {
q. push ( x* n+ y) ;
flag[ x* n+ y] = true ;
}
}
}
return square;
}
int maxAreaOfIsland ( vector< vector< int >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
int maxSquare= 0 ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
if ( grid[ i] [ j] == 1 && ! flag[ i* n+ j] ) maxSquare= max ( maxSquare, bfs ( i, j, grid) ) ;
}
}
return maxSquare;
}
} ;
岛屿的周长需要注意的是,之前做BFS/DFS的题基本都是check某个节点的周边四个节点,而这题严格意义上来说是check某个节点的四条边,也算提醒了一下自己不要固定思维 class Solution {
public :
bool flag[ 10010 ] ;
int dfs ( int x, int y, vector< vector< int >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
if ( x< 0 || x>= m|| y< 0 || y>= n) return 1 ;
if ( grid[ x] [ y] == 0 ) return 1 ;
if ( flag[ x* n+ y] ) return 0 ;
flag[ x* n+ y] = true ;
return dfs ( x- 1 , y, grid) + dfs ( x+ 1 , y, grid) + dfs ( x, y- 1 , grid) + dfs ( x, y+ 1 , grid) ;
}
int islandPerimeter ( vector< vector< int >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
int sum= 0 ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
if ( grid[ i] [ j] == 1 && ! flag[ i* n+ j] ) {
sum= dfs ( i, j, grid) ;
break ;
}
}
}
return sum;
}
} ;
class Solution {
public :
bool flag[ 10010 ] ;
void bfs ( int x, int y, vector< vector< int >> & grid, int & sum) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
queue< int > q;
q. push ( x* n+ y) ;
flag[ x* n+ y] = true ;
int dx[ 4 ] = { 0 , 1 , 0 , - 1 } , dy[ 4 ] = { 1 , 0 , - 1 , 0 } ;
while ( ! q. empty ( ) ) {
int t= q. front ( ) ;
q. pop ( ) ;
for ( int i= 0 ; i< 4 ; i++ ) {
int x= t/ n+ dx[ i] ;
int y= t% n+ dy[ i] ;
if ( x< 0 || x>= m|| y< 0 || y>= n) sum+= 1 ;
else if ( grid[ x] [ y] == 0 ) sum+= 1 ;
else if ( flag[ x* n+ y] ) sum+= 0 ;
else {
q. push ( x* n+ y) ;
flag[ x* n+ y] = true ;
}
}
}
}
int islandPerimeter ( vector< vector< int >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
int sum= 0 ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
if ( grid[ i] [ j] == 1 && ! flag[ i* n+ j] ) {
bfs ( i, j, grid, sum) ;
break ;
}
}
}
return sum;
}
} ;
腐烂的橘子深度优先 不能保证第一次搜到的就是最短路。 class Solution {
public :
int orangesRotting ( vector< vector< int >> & grid) {
int m= grid. size ( ) ;
int n= grid[ 0 ] . size ( ) ;
queue< int > q;
int cnt= 0 ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
if ( grid[ i] [ j] == 2 ) q. push ( i* n+ j) ;
else if ( grid[ i] [ j] == 1 ) cnt++ ;
}
}
int dx[ 4 ] = { 1 , 0 , - 1 , 0 } , dy[ 4 ] = { 0 , 1 , 0 , - 1 } ;
int time= 0 ;
while ( ! q. empty ( ) ) {
auto t= q. front ( ) ;
q. pop ( ) ;
for ( int i= 0 ; i< 4 ; i++ ) {
int x= t/ n+ dx[ i] ;
int y= t% n+ dy[ i] ;
if ( x>= 0 && x< m && y>= 0 && y< n && grid[ x] [ y] == 1 ) {
cnt-- ;
grid[ x] [ y] = grid[ t/ n] [ t% n] + 1 ;
q. push ( x* n+ y) ;
time= grid[ x] [ y] - 2 ;
}
}
}
if ( ! cnt) return time;
return - 1 ;
}
} ;
01 矩阵 https://leetcode.cn/problems/01-matrix/ class Solution {
public :
vector< vector< int >> updateMatrix ( vector< vector< int >> & mat) {
int m= mat. size ( ) ;
int n= mat[ 0 ] . size ( ) ;
queue< pair< int , int >> q;
vector< vector< int >> seen ( m, vector< int > ( n, 0 ) ) ;
for ( int i= 0 ; i< m; i++ ) {
for ( int j= 0 ; j< n; j++ ) {
if ( ! mat[ i] [ j] ) {
q. push ( { i, j} ) ;
seen[ i] [ j] = 1 ;
}
}
}
vector< vector< int >> res ( m, vector< int > ( n, 0 ) ) ;
int dx[ 4 ] = { 1 , 0 , - 1 , 0 } , dy[ 4 ] = { 0 , 1 , 0 , - 1 } ;
while ( q. size ( ) ) {
auto t= q. front ( ) ;
q. pop ( ) ;
for ( int i= 0 ; i< 4 ; i++ ) {
int x= t. first+ dx[ i] ;
int y= t. second+ dy[ i] ;
if ( x>= 0 && x< m && y>= 0 && y< n && ! seen[ x] [ y] ) {
res[ x] [ y] = res[ t. first] [ t. second] + 1 ;
seen[ x] [ y] = 1 ;
q. push ( { x, y} ) ;
}
}
}
return res;
}
} ;
有向图的拓扑序列 https://www.acwing.com/problem/content/850/ # include <iostream> # include <cstring> using namespace std;
const int N= 1e5 + 10 ;
int n, m;
int h[ N] , e[ 2 * N] , ne[ 2 * N] , idx;
int d[ N] ;
int queue[ N] , hh, tt;
void init ( ) {
hh= 0 , tt= - 1 ;
memset ( h, - 1 , sizeof ( h) ) ;
}
void add ( int a, int b) {
e[ idx] = b;
ne[ idx] = h[ a] ;
h[ a] = idx++ ;
d[ b] ++ ;
}
void bfs ( ) {
for ( int i= 1 ; i<= n; i++ ) {
if ( ! d[ i] ) queue[ ++ tt] = i;
}
while ( hh<= tt) {
int x= queue[ hh++ ] ;
for ( int i= h[ x] ; i!= - 1 ; i= ne[ i] ) {
int b= e[ i] ;
d[ b] -- ;
if ( ! d[ b] ) queue[ ++ tt] = b;
}
}
if ( tt== n- 1 ) {
for ( int i= 0 ; i< n; i++ ) cout<< queue[ i] << " " ;
cout<< endl;
} else {
cout<< - 1 << endl;
}
}
int main ( ) {
ios:: sync_with_stdio ( false ) ;
cin. tie ( 0 ) , cout. tie ( 0 ) ;
cin>> n>> m;
init ( ) ;
while ( m-- ) {
int x, y;
cin>> x>> y;
add ( x, y) ;
}
bfs ( ) ;
return 0 ;
}
课程表 II https://leetcode.cn/problems/course-schedule-ii/ class Solution {
public :
int h[ 2010 ] , e[ 4020 ] , ne[ 4020 ] , idx;
int d[ 2010 ] ;
int q[ 2010 ] , hh, tt;
void init ( ) {
hh= 0 , tt= - 1 ;
memset ( h, - 1 , sizeof ( h) ) ;
}
void add ( int a, int b) {
e[ idx] = b;
ne[ idx] = h[ a] ;
h[ a] = idx++ ;
d[ b] ++ ;
}
vector< int > bfs ( int n) {
for ( int i= 0 ; i< n; i++ ) {
if ( ! d[ i] ) q[ ++ tt] = i;
}
while ( hh<= tt) {
int x= q[ hh++ ] ;
for ( int i= h[ x] ; i!= - 1 ; i= ne[ i] ) {
int j= e[ i] ;
d[ j] -- ;
if ( ! d[ j] ) q[ ++ tt] = j;
}
}
vector< int > res;
if ( tt== n- 1 ) {
for ( int i= 0 ; i< n; i++ ) res. push_back ( q[ i] ) ;
}
return res;
}
vector< int > findOrder ( int numCourses, vector< vector< int >> & prerequisites) {
init ( ) ;
for ( int i= 0 ; i< prerequisites. size ( ) ; i++ ) {
int a= prerequisites[ i] [ 1 ] ;
int b= prerequisites[ i] [ 0 ] ;
add ( a, b) ;
}
return bfs ( numCourses) ;
}
} ;
课程表 https://leetcode.cn/problems/course-schedule/ class Solution {
public :
int h[ 2010 ] , e[ 4020 ] , ne[ 4020 ] , idx;
int d[ 2010 ] ;
int q[ 2010 ] , hh, tt;
void init ( ) {
hh= 0 , tt= - 1 ;
memset ( h, - 1 , sizeof ( h) ) ;
}
void add ( int a, int b) {
e[ idx] = b;
ne[ idx] = h[ a] ;
h[ a] = idx++ ;
d[ b] ++ ;
}
vector< int > bfs ( int n) {
for ( int i= 0 ; i< n; i++ ) {
if ( ! d[ i] ) q[ ++ tt] = i;
}
while ( hh<= tt) {
int x= q[ hh++ ] ;
for ( int i= h[ x] ; i!= - 1 ; i= ne[ i] ) {
int j= e[ i] ;
d[ j] -- ;
if ( ! d[ j] ) q[ ++ tt] = j;
}
}
vector< int > res;
if ( tt== n- 1 ) {
for ( int i= 0 ; i< n; i++ ) res. push_back ( q[ i] ) ;
}
return res;
}
bool canFinish ( int numCourses, vector< vector< int >> & prerequisites) {
init ( ) ;
for ( int i= 0 ; i< prerequisites. size ( ) ; i++ ) {
int a= prerequisites[ i] [ 1 ] ;
int b= prerequisites[ i] [ 0 ] ;
add ( a, b) ;
}
if ( bfs ( numCourses) . size ( ) == 0 ) return false ;
return true ;
}
} ;
实现Trie(前缀树) https://leetcode.cn/problems/implement-trie-prefix-tree/?envType=study-plan-v2&id=top-100-liked typedef struct Node {
struct Node * letter[ 26 ] ;
bool isEnd;
} Trie;
Trie* trieCreate ( ) {
Trie* p= ( Trie* ) malloc ( sizeof ( Trie) ) ;
memset ( p-> letter, NULL , sizeof ( p-> letter) ) ;
p-> isEnd= false;
return p;
}
void trieInsert ( Trie* obj, char * word) {
for ( int i= 0 ; word[ i] != '\0' ; i++ ) {
if ( obj-> letter[ word[ i] - 'a' ] ) {
obj= obj-> letter[ word[ i] - 'a' ] ;
} else {
obj-> letter[ word[ i] - 'a' ] = trieCreate ( ) ;
obj= obj-> letter[ word[ i] - 'a' ] ;
}
}
obj-> isEnd= true;
}
bool trieSearch ( Trie* obj, char * word) {
for ( int i= 0 ; word[ i] ; i++ ) {
if ( obj-> letter[ word[ i] - 'a' ] ) {
obj= obj-> letter[ word[ i] - 'a' ] ;
} else {
return false;
}
}
if ( obj-> isEnd) return true;
return false;
}
bool trieStartsWith ( Trie* obj, char * prefix) {
for ( int i= 0 ; prefix[ i] ; i++ ) {
if ( obj-> letter[ prefix[ i] - 'a' ] ) {
obj= obj-> letter[ prefix[ i] - 'a' ] ;
} else {
return false;
}
}
return true;
}
void trieFree ( Trie* obj) {
obj= trieCreate ( ) ;
}